Machine Learning을 공부하다 보면 배열의 차원을 낮추는 경우가 종종 발생한다.
예를 들어 아래와 같이 2차원 배열인 array_2d가 있다고 할 때,
차원을 하나 낮춘다는 의미는 2차원 배열이 1차원 배열이 되는 것이다.

그런데..!!
차원을 낮출 땐 주의사항이 있다.
바로 array_2d의 데이터 변화가 array_1d에 영향을 미치느냐 하는 것이다.
결론부터 말하면,
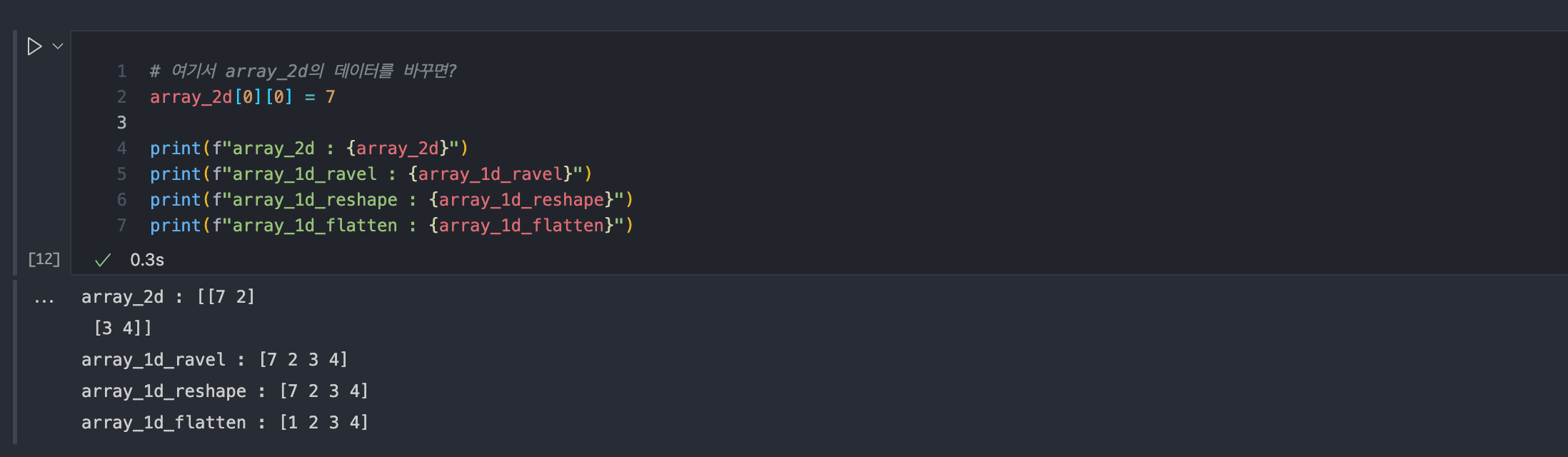
아래처럼 array_2d의 첫번째 원소값을 바꿀 경우
ravel(), reshape() 으로 차원을 낮춘 array_1d_ravel 과 array_1d_reshape 의 데이터는 바뀌고,
flatten()으로 차원을 낮춘 array_1d_flatten은 데이터가 바뀌지 않는다.
잘 모르고 사용하다가 예상치 못하게 변하면 안될 데이터가 변할수도, 변해야할 데이터가 안변할 수도 있는 것이다...
그렇다면 왜 이런 차이점이 발생할까?
이는 차원을 낮출 때 원본 데이터를 그대로 참조하느냐, 아니면 따로 복사해서 사용하느냐의 차이이다.
아래는 각 1차원 배열들의 base들을 출력한 모습이다.

array_1d_ravel, array_1d_reshape 은 base가 array_2d를 가리키고 있지만 array_1d_flatten은 base가 None이다.
base가 다른 이유는
ravel(), reshape() 함수는 원본 객체의 view를 이용해 원본 데이터를 그대로 얻어오고
flatten() 함수는 원본 객체의 copy를 이용해 원본 데이터를 얻어오기 때문이다.
view는 C/C++등 다른 프로그래밍 언어에서 사용하는 '참조(reference)' 개념과 유사하다.
원본 데이터와 복제본이 서로 영향을 미친다는 뜻이다.
반면 copy는 원본 데이터와 복제본이 서로 영향을 미치지 않는다.
원본 데이터를 아예 새로운 메모리 공간에 복사하고 이 공간을 복제본이 사용하기 때문이다.
view와 copy의 작동 방식에 대해 더 궁금할 경우 여기에 잘 정리되어 있다.
그래서 결론은,,
차원을 낮출 때 ravel(), reshape()은 원본 데이터와 서로 영향을 주고받고,
flatten()은 영향을 주고받지 않는다!
'Development Experience > Python' 카테고리의 다른 글
| Python 에서 GIL, 멀티스레딩, 멀티프로세싱 (0) | 2026.01.13 |
|---|---|
| 연속적인 DataFrame의 값들을 몇 개의 그룹으로 나누고 싶을 때 (0) | 2023.07.16 |
