EDA 과정에서 도움이 되는 기본적인 Pandas 함수들을 titanic 데이터를 활용하여 알아보자.
우선, 아래는 예제 데이터이다.

위 데이터를 가지고 Pandas 함수를 사용해보자..!
1. shape
데이터의 행과 열을 (행, 열) 형식으로 표시해준다.
titanic_train.shape
2. dtypes
데이터의 각 컬럼별 자료형을 알려준다.
titanic_train.dtypes
3. columns
데이터의 컬럼들을 알려준다.
titanic_train.columns
4. head & tail
데이터의 일부 row를 앞에서부터 보고 싶을 경우 head 함수를, 뒤에서부터 보고 싶을 경우 tail 함수를 사용한다.
기본 갯수는 5개이며 직접 지정 가능하다.
titanic_train.head()
titanic_train.head(10)
titanic_train.tail()
titanic_train.tail(10)
5. [ : ]
이건 파이썬 기본 기능이긴 한데 특정 row의 데이터를 보고 싶을 때 유용해서 넣어보았다.
titanic_train[3:5]
6. info
데이터의 전반적인 내용을 개략적으로 알려준다.
titanic_train.info()
7. describe
이 함수는 괄호를 붙일 때와 아닐 때 다른 값을 표시한다.
describe는 데이터 전체 중 일부를 표시해 주는데 사실 이 기능은 head나 tail, [:] 연산과 겹치는 부분이 있어서 많이 애용하진 않는다.
반면 describe()는 컬럼별 평균값, 갯수, 최대/최소값, 표준편차, 하위 25%/50%/75% 값을 표시해주기 때문에 각 컬럼별 특징을 알아내는데 도움이 된다.
titanic_train.describe()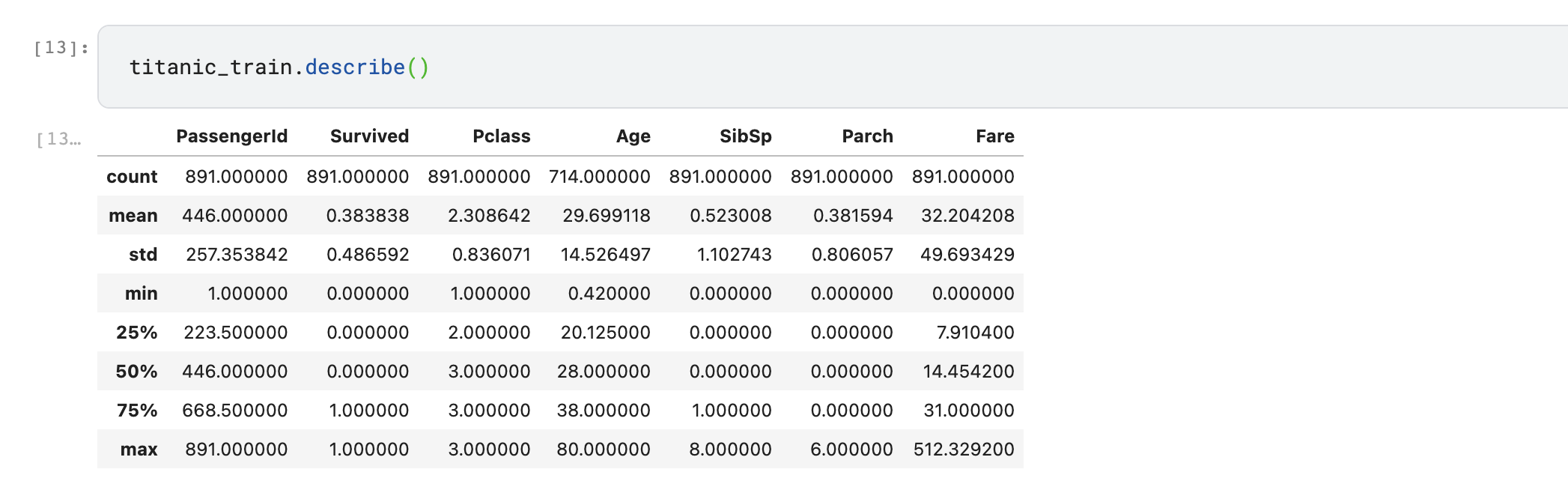
titanic_train.describe
8. value_counts
특정 column에서 각각의 값들이 몇개씩 있는지 알려준다.
titanic_train['Survived'].value_counts()
titanic_train['Embarked'].value_counts()
반응형
'Data Analysis > EDA' 카테고리의 다른 글
| 3. DataFrame의 column별 데이터의 분포가 보고 싶을 땐 seaborn.displot() (0) | 2023.07.14 |
|---|---|
| 1. 결측값을 한눈에 보여주는 missingno (0) | 2023.07.01 |

