각 컬럼별로 어느 구간에 데이터가 몰려있는지 알고 싶다면 seaborn의 displot을 사용해보자.
import random
import seaborn as sns
rand_data = []
for _ in range(1, 10000): # 10000개의 난수 생성
rand_data.insert(0, random.randrange(0, 10001)) # 생성된 난수는 0~10000 사이의 값을 가짐
sns.displot(data = rand_data, kind='kde').set(title='Random Values')위의 예제는 0~10000개의 난수를 생성하여 rand_data 배열에 넣고 이 난수들의 분포를 seaborn을 통해 시각화하는 코드이다.
참고로, 각 난수는 0~10000 사이의 값을 지닌다.
위 코드를 실행한 결과는...
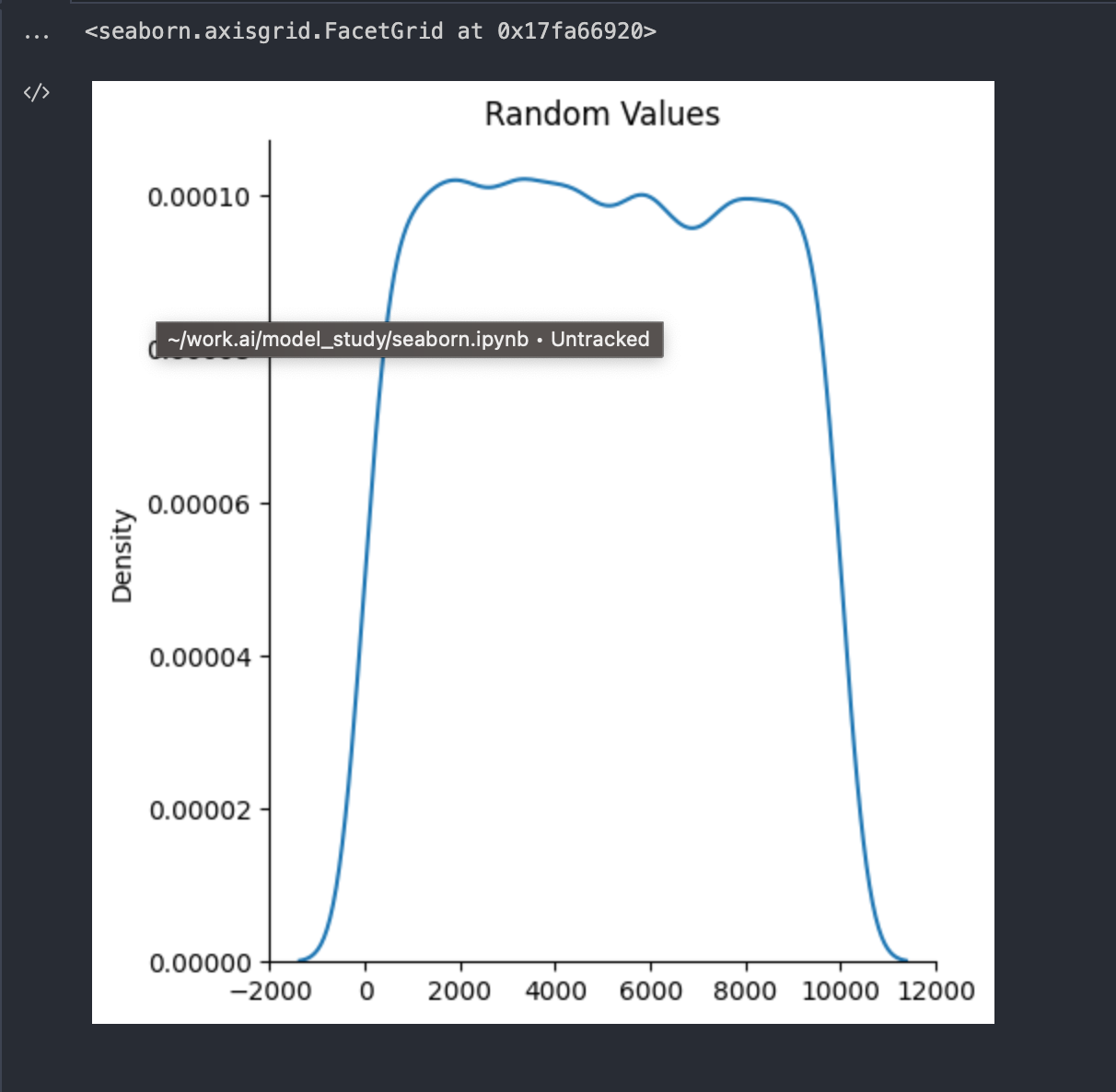
각 데이터가 0~10000 구간 사이에 걸쳐 골고루 생성되었음을 확인할 수 있다.
그렇다면 두번째로,
난수를 0, 1000, 2000... 9000, 10000 이렇게 1000의 배수로만 생성하면 어떻게 될까?
rand_data_2 = []
for _ in range(1, 10000):
rand_data_2.insert(0, random.randrange(0, 10) * 1000) # 생성된 난수는 0, 1000, 2000... 9000, 1000 의 값 중 하나를 가짐
sns.displot(data = rand_data_2, kind='kde').set(title="Random Values 2")
위 코드는 1000의 배수로만 난수를 생성하여 rand_data_2 배열에 저장하고,
그 난수들의 분포를 시각화하는 코드이다.
그 결과는..
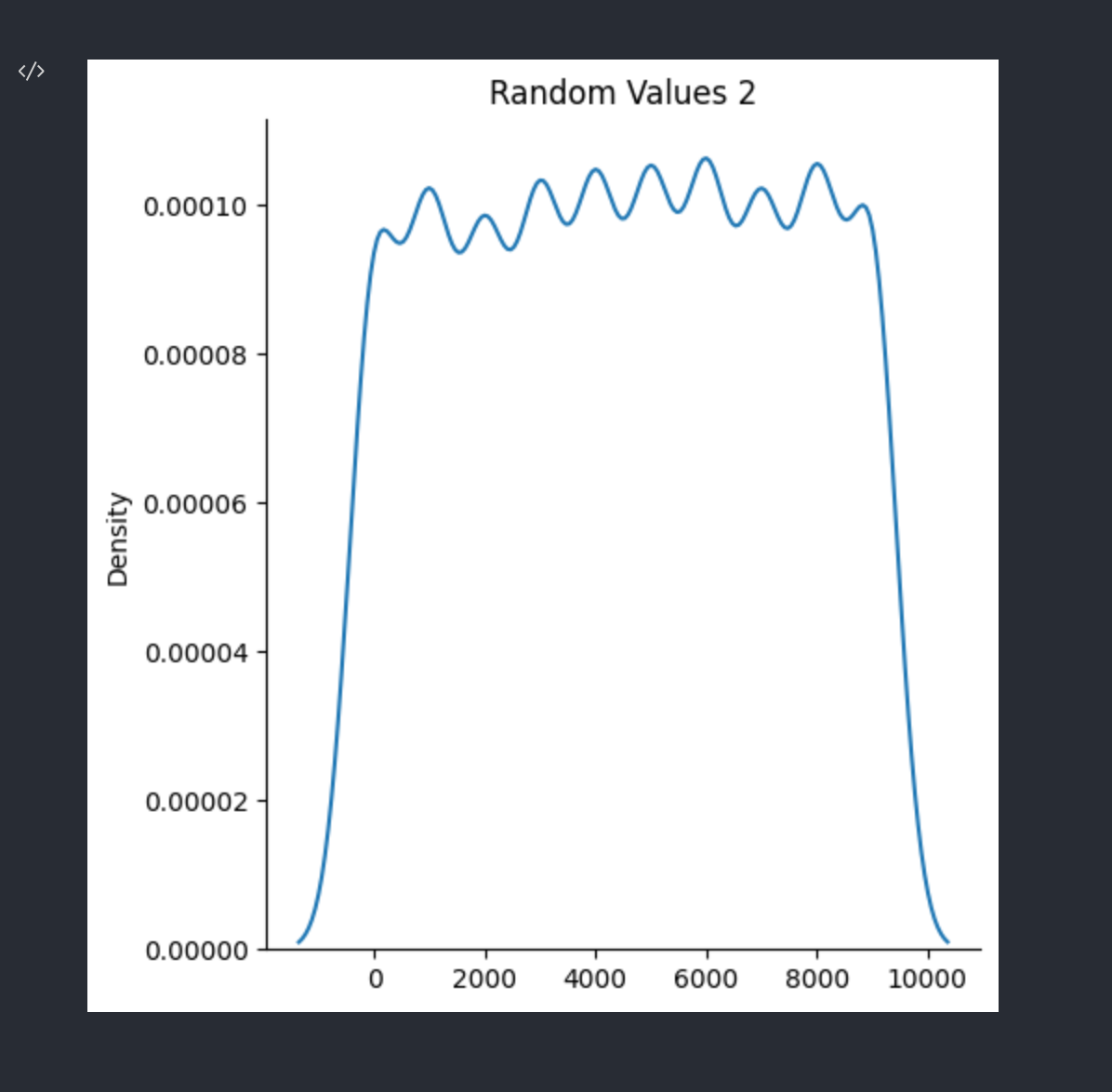
좀전의 분포보다 훨씬 더 각이 진 모양으로 나타난다. 난수가 전 범위가 아닌 1000의 배수일 때만 나타나기 때문이다.
그럼 마지막으로,
9000개의 난수가 0~3000의 값을 가지고
마지막 1000개의 난수가 0~10000의 값을 가진다면 그래프는 어떻게 나올까?
rand_data_3 = []
for i in range(1, 10000):
if i < 9001: # 전체 데이터의 90%
rand_data_3.insert(0, random.randrange(0, 3001)) # 생성된 난수 중 9000개는 0~3000 사이의 값을 가짐
else: # 전체 데이터의 10%
rand_data_3.insert(0, random.randrange(0, 10001)) # 생성된 난수 중 마지막 1000개는 0~10000 사이의 값을 가짐
sns.displot(data = rand_data_3, kind='kde').set(title='Random Values 3')
위 코드를 실행한 결과는 다음과 같다.

전체 데이터의 90%가 0~3000 사이의 값을 가지기 때문에 그래프 상에서도 이러한 비중이 잘 시각화되어 있다..!!
참고로, displot()의 kind를 바꾸면 다른 형태의 그래프도 볼 수 있다.
kind='hist' 로 설정하면 막대 모양의 차트를 볼 수 있다.
sns.displot(data = rand_data_3, kind='hist').set(title='Random Values 3')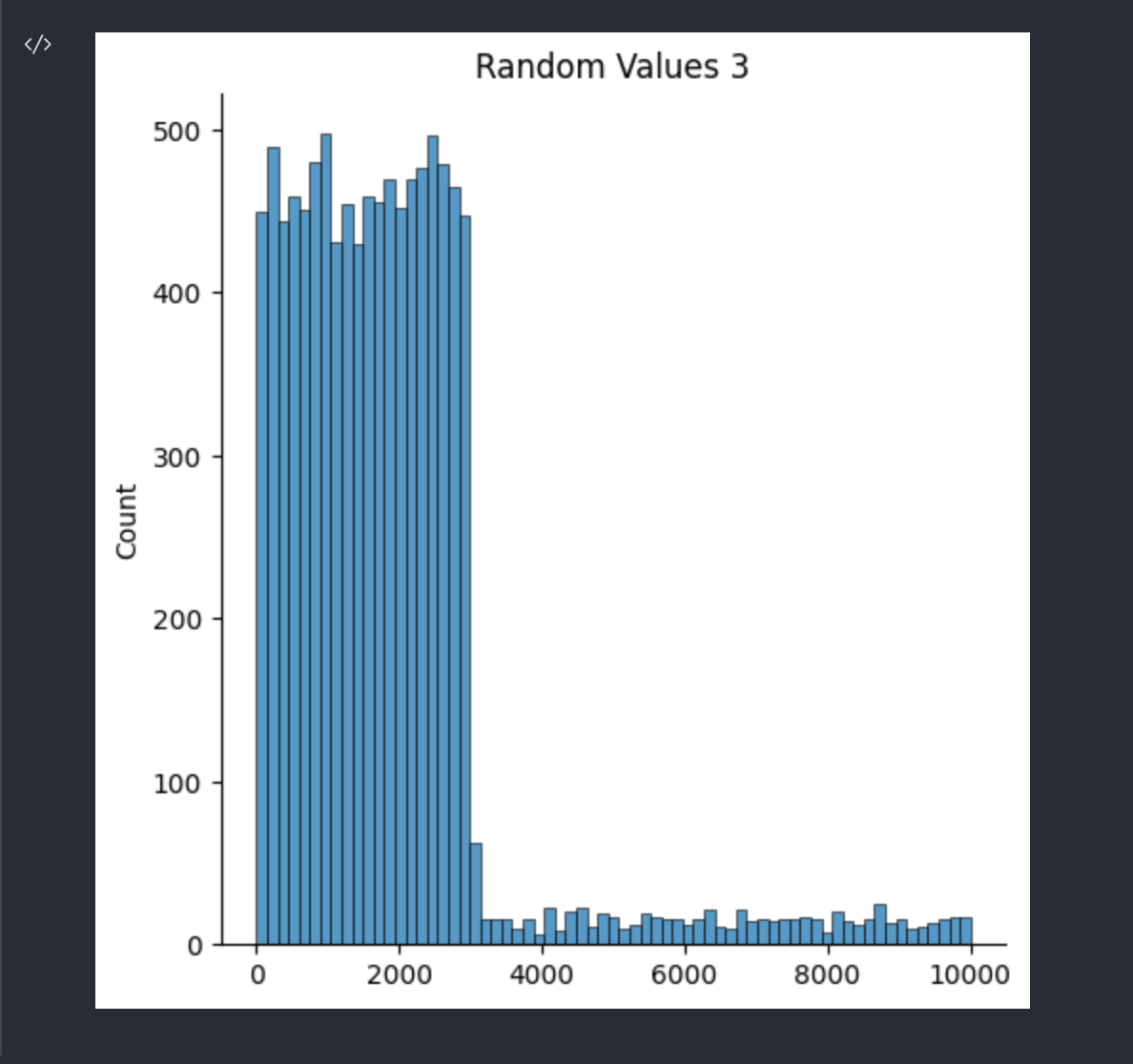
kind='ecdf' 로 설정하면 데이터의 누적량 변화를 볼 수 있다. (ecdf = Empirical Cumulative Distributions)
sns.displot(data = rand_data_3, kind='ecdf').set(title='Random Values 3')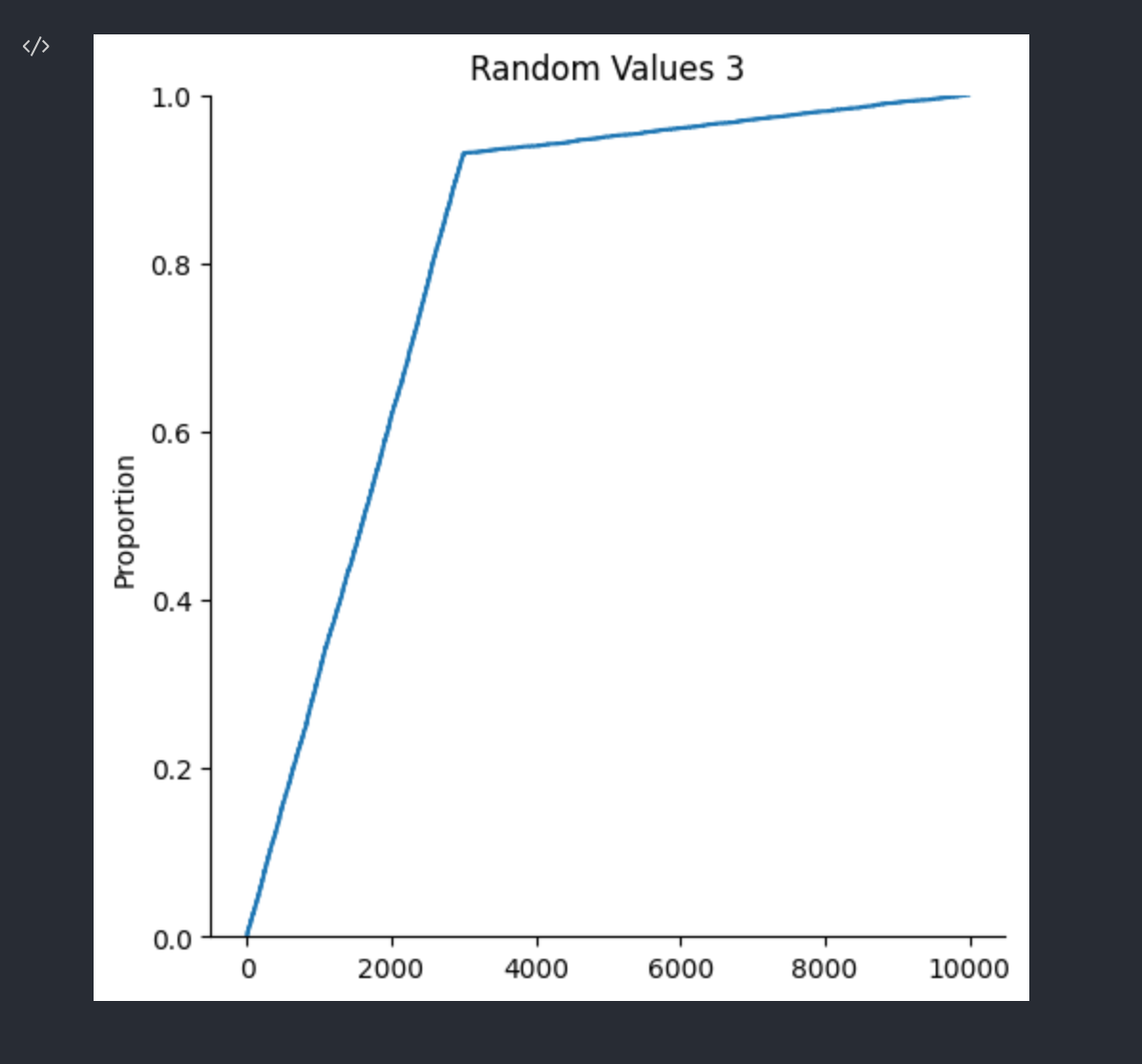
'Data Analysis > EDA' 카테고리의 다른 글
| 2. EDA에 도움되는 파이썬 Pandas 함수들 (0) | 2023.07.03 |
|---|---|
| 1. 결측값을 한눈에 보여주는 missingno (0) | 2023.07.01 |

